





1. Introduction▲
ANTLRANother Tool for Language Recognigtion (AnotherTool for LanguageRecognigtion) est un générateur d'analyseurs. C'est un outil qui propose un framework pour construire des reconnaisseurs, des compilateurs ou des traducteurs à partir de descriptions grammaticales qui peuvent éventuellement contenir des instructions écrites en Java, C++, C#, etc. Un générateur d'analyseurs est un outil qui lit une grammaire en entrée et la convertit en un programme qui peut reconnaître un texte et le traiter suivant les règles de cette grammaire. ANTLRANother Tool for Language Recognigtion a été développé par Terrence Parr dans le langage Java, mais il peut générer des analyseurs dans un code écrit dans l'un de ses nombreux langages de programmation cibles (Java, Ruby, Python, C, C++, C#). Dans le cadre de ce tutoriel, nous choisirons Java comme langage cible.
En plus du générateur d'analyseur, ANTLRANother Tool for Language Recognigtion fournit d'autres fonctionnalités y afférentes telles que la construction d'arbres, l'insertion des actions dans les règles de grammaire, la gestion d'erreurs et le débogage. Il existe un environnement d'utilisation graphique appelé AntlrWorks. Nous ne l'abordons pas dans ce tutoriel. ANTLRANother Tool for Language Recognigtion et AntlrWorks sont libres et open source. Ils peuvent être téléchargés à l'adresse www.antlr.org. Dans ce tutoriel, nous utiliserons la version Antlr3.
Après les généralités sur la notion d'analyseur, nous aborderons les règles d'écriture de grammaires sous ANTLRANother Tool for Language Recognigtion. Ensuite, nous verrons comment définir et générer des analyseurs. Nous terminerons par un exemple qui illustrera les notions apprises.
2. Généralités▲
S'il est vrai que la connaissance de la théorie des langages et des techniques de compilation est un atout, il faut souligner que les concepts-clés à cerner pour débuter avec Antlr sont ceux de grammaire, d'analyse lexicale et d'analyse syntaxique. Cependant dans une prochaine édition, nous aborderons le concept d'analyseur d'arbres qui fonctionne sur le même principe.
Dans cette section, vous apprendrez non seulement ce que c'est qu'une grammaire, un analyseur lexical ou syntaxique, mais aussi ce qu'on peut réaliser avec Antlr, les langages cibles et la procédure à suivre pour générer des analyseurs.
2-1. La notion de grammaire▲
Une grammaire spécifie les mots-clés (encore appelés tokens) utilisables dans un langage et décrit les constructions utilisant ces mots qui sont admises par ledit langage. Pour réaliser les analyses lexicale et syntaxique, il faut spécifier une grammaire qui décrit la façon de regrouper le flux de caractères en un flux de tokens puis d'analyser le flux de tokens sortant.
Le mot token est un anglicisme utilisé pour désigner une
entité
(ou
unité
)
lexicale
, dans le cadre de l'
analyse lexicale
.
Il existe, en fait, trois tâches distinctes que l'on souhaiterait effectuer à l'aide d'une grammaire : la reconnaissance , qui correspond au calcul de l'appartenance d'un mot à un langage ; l'analyse (ou le parsage), qui correspond au calcul de tous les arbres d'analyse possibles pour un énoncé ; la génération, qui correspond à la production de tous les mots du langage décrit par la grammaire.
2-2. L'analyse lexicale▲
L'analyse lexicale doit permettre de déterminer correctement les chaînes comprises dans le texte source. Le texte source est fourni à l'analyseur caractère par caractère. Ce dernier a pour travail de quantifier le groupe de caractères significatifs et de le catégoriser au point qu'il ait un sens pour l'analyseur syntaxique. Tout caractère ou groupe de caractères ainsi quantifié est appelé token.
Ainsi dans l'instruction Pascal suivante :
aire := base ∗ hauteur/2
L'analyse lexicale reconnaît les lexèmes suivants :

La tâche principale d'un analyseur lexical (appelé lexer ou tokenizer ou encore scanner) est de lire les caractères d'entrée et de produire comme résultat une suite d'unités lexicales que l'analyseur syntaxique va utiliser. C'est en général un sous-module de l'analyseur syntaxique qui lui commande la prochaine unité lexicale à extraire.
2-3. L'analyse syntaxique▲
L'analyse syntaxique regroupe les unités lexicales en structures grammaticales en suivant les règles figurant dans une grammaire. En effet, le lexer regroupe une suite de caractères qu'il reconnaît dans le flux d'entrée selon une sémantique individuelle ; il ne considère pas la sémantique globale de tout le flux d'entrée. Ceci est le rôle de l'analyseur syntaxique qui organise les tokens qu'il reçoit en des suites grammaticalement correctes.
Un analyseur syntaxique (parser) prend en entrée une chaîne d'unités lexicales fournie par l'analyseur lexical et détermine si celle-ci fait partie du langage en construisant l'arbre syntaxique correspondant.
2-4. Que peut-on réaliser avec ANTLR ?▲
Antlr a trois cas d'utilisation principaux. Il peut être utilisé pour implémenter :
- un validateur ou reconnaisseur. Antlr génère le code qui permet de valider si le texte d'entrée respecte les règles de grammaire. Ici, la grammaire n'intègre pas d'actions (instructions écrites dans le langage cible) ni de règles de réécriture ;
- un processeur. Antlr génère du code qui valide et traite le texte d'entrée. La grammaire intègre des actions qui peuvent être des instructions de calcul, des accès à une base de données, etc. Cependant, il n'y a pas de règle de réécriture ;
- un traducteur. Antlr génère le code qui valide et traduit le texte d'entrée dans un autre format. Par exemple, il peut servir à traduire un texte écrit dans un langage en un texte écrit dans un autre langage. Ici, on retrouvera des actions, notamment les instructions d'affichage (println).
2-5. Les langages cibles▲
À partir d'une grammaire spécifiée sous le formalisme adéquat, Antlr peut générer des analyseurs écrits dans plusieurs langages cibles. Comme langages cibles, on peut citer : C++, Java, Python, C #.
2-6. BNF ET EBNF▲
BNF et EBNF sont à la base de la définition de la syntaxe des règles sous Antlr.
John Backus, créateur de Fortran, a conçu en 1959 une notation formelle permettant de décrire la syntaxe de n'importe quel langage. Elle fut utilisée à l'époque pour présenter la syntaxe d'Algol 58. Peter Naur a ensuite repris ses travaux en préparation à Algol 60, et ses modifications font depuis partie intégrante de la notation BNF : Backus Naur Form.
BNF se base sur un nombre donné de métasymboles, avec lesquels décrire une syntaxe. Ces métasymboles sont combinés à des symboles « terminaux » (catégories définies par la syntaxe) et « non terminaux » (mots-clés du langage lui-même). Il permet par exemple l'usage des symboles suivants :
| Symbole | Utilisation | Signification | Exemple |
| ::= ou := | Attribution ou définition |
« est défini comme »
« contient » |
x ::= "lapin" |
| | | Alternatives | « ou » |
x | y
x |y|z |
| < et > | Encadrent les symboles non terminaux | <symboleNonTerminal> | |
| ; | Fin d'une définition | ||
Par exemple, pour définir les voyelles disponibles dans l'alphabet :
voyelle ::= "A" | "E" | "I" | "O" | "U" ;
L a notation BNF a ensuite été étendue sous le nom EBNF (Extended BNF). Cette extension permettait l'usage d'une syntaxe proche des expressions régulières pour décrire certains aspects, comme la répétition ou le regroupement de blocs.
| Symbole | Signification |
| x ? | 0 ou une occurrence de x |
| x + | Au moins une occurrence de x |
| x * | 0 ou plusieurs occurrences de x |
| xy | x suivi de y |
| ( xy ) | Regroupement de la séquence xy, permettant de la différencier d'autres séquences |
Depuis lors, la plupart des langages informatiques sont décrits suivant cette notation. EBNF se présente comme un métalangage concis et précis, idéal pour présenter toutes les facettes d'une syntaxe. Il interdit toute forme d'ambiguïté concernant l'interprétation de la spécification.
2-7. Comment procéder ?▲
Pour réaliser les analyses lexicale et syntaxique avec Antlr, il faut :
- Créer un fichier d'extension .g définissant les unités lexicales et syntaxiques de la grammaire. Antlr génèrera lui-même par la suite les classes correspondant au lexer et au parser ;
- Créer et paramétrer un fichier Build.xml qui définit les actions à effectuer lors de la compilation des fichiers .g ;
- Utiliser le compilateur Ant pour générer les analyseurs spécifiés dans la grammaire ;
- Définir un programme principal dans le langage cible qui utilisera les analyseurs (lexer et le parser) générés pour effectuer le travail souhaité.
3. Écriture de la grammaire▲
L'écriture d'une grammaire sous Antlr obéit à un formalisme qui doit être respecté aussi bien en ce qui concerne la structure du fichier qu'en ce qui concerne l'écriture des règles. Pour un débutant, il est conseillé de s'inspirer d'une grammaire existante.
3-1. Structure d'un fichier grammaire▲
Une grammaire Antlr est constituée de plusieurs rubriques dont certaines sont optionnelles. La structure générale est la suivante :
Header {
/* le texte mis dans cette rubrique s'affichera tel quel dans toutes les classes définies dans ce fichier. Par exemple, nous y mettrons le nom du package auquel appartiendront toutes les classes générées */
}
{ /* Le texte de cette rubrique (non nommée) s'affichera tel quel au début de la classe qui sera générée à partir de la définition de classe qui suit */
// Nous y inscrirons par exemple les importations de packages.
}
class <nom_analyseur> extends <nom_classe_mere>
options{ // mettre ici les options spécifiques à l'analyseur }
tokens {
// définir ici les tokens imaginaires ou les littéraux
}
<nom_regle1>: corps de la regle;
…
<nom_reglen>: corps de la regle;
/* la définition de la dernière règle marque la fin de la grammaire */

|
Une grammaire peut contenir plusieurs classes définies dans le même fichier. Dans ce cas, la portée d'une classe s'étend de sa déclaration jusqu'à la déclaration de la prochaine classe. Par exemple, il est de coutume de définir dans le même fichier la classe qui générera l'analyseur lexical et la classe qui générera l'analyseur syntaxique. Cependant, rien ne nous empêche de les définir dans des fichiers distincts. |
3-2. Syntaxe d'une règle sous Antlr▲
Une règle définit une construction lexicale ou syntaxique reconnaissable par l'analyseur et éventuellement les actions à envisager lorsqu'une telle construction est rencontrée. Une telle construction peut aussi bien utiliser les constructions d'autres règles. Une règle est identifiée par un nom.
L'écriture d'une règle de la grammaire obéit au formalisme suivant :
Nom_de_la-regle[arguments] returns [valeur_de_retour]
options{ // les options liées uniquement à cette règle }
: // corps de la règle...
;3-3. Les multiplicités▲
Dans le corps d'une règle, des formalismes sont utilisés pour caractériser la multiplicité d'une expression dans une construction. Ces formalismes sont :
- (expression) * : zéro ou plus. Ceci signifie que l'expression entre parenthèses peut être rencontrée zéro ou plusieurs fois dans la construction à reconnaître ;
- (expression) + : un ou plus. Ceci signifie que l'expression entre parenthèses peut être rencontrée une ou plusieurs fois dans la construction à reconnaître ;
- (expression) ? : zéro ou un. Ceci signifie que l'expression entre parenthèses peut être rencontrée une fois ou ne pas du tout être rencontrée dans la construction à reconnaître.
Nombre_decimal:
('0' .. '9')+(',' ('0'..'9')+)?
;3-4. Les alternatives▲
Lorsque plusieurs constructions se rapportent au même lexème, au lieu de définir plusieurs règles, il est judicieux de les regrouper dans une seule règle à plusieurs alternatives. Les alternatives sont séparées les unes des autres par un "|" dans le corps de la règle.
nom-regle[arguments] returns [valeur_de_retour]
options{ // les options liées uniquement à cette règle }
: alternative 1
| alternative 2
| …
| alternative n
;Exemple
Pour qu'un analyseur reconnaisse les espacements (retour à la ligne, retour chariot, tabulation, etc.) dans le flux d'entrée, au lieu de définir une règle pour chaque type d'espacement, il est préférable de définir une seule règle à plusieurs alternatives comme suit :
White_Space
: ' '
| '\t'
| '\r' '\n'
| '\n'
;3-5. Les options ▲
Vous avez pu remarquer dans la structure d'une grammaire qu'il figure plusieurs endroits dans lesquels on peut définir des options. En effet, les options permettent de donner certaines fonctionnalités à notre grammaire. Elles peuvent concerner toute la grammaire, juste une classe ou bien être spécifique à une règle.
Dans la section Options d'une grammaire ANTLR, vous pouvez spécifier une série de clé/valeur qui modifient la façon dont ANTLR génère du code. Ces options affectent globalement tous les éléments contenus dans la grammaire, sauf si vous les annulez dans une règle. Ce paragraphe décrit toutes les options disponibles.
La section des options doit venir après l'en-tête de la grammaire et doit avoir la forme suivante :
options {
nom1 = valeur1;
nom2 = valeur2;
...
}Les noms des options sont toujours des identificateurs, mais les valeurs peuvent être des identificateurs, des chaînes de littéraux entre des guillemets simples, des nombres entiers, ou le littéral spécial * (l'astérisque souvent utilisable uniquement avec l'option k). Les valeurs sont toutes des littéraux et, par conséquent, ne peuvent pas être des noms d'option. Pour les chaînes littérales formées d'un seul mot comme « Java », vous pouvez l'écrire tout simplement, comme indiqué ci-après :
options {
language=Java;
}La liste qui suit résume les options ANTLR au niveau de la grammaire.
Language
Précisez le langage cible dans lequel ANTLR devra générer les analyseurs.
ANTLR utilise le CLASSPATH pour trouver le répertoire org/antlr/ codegen/ templates/Java ; dans ce cas, c'est Java le langage cible, et c'est lui par défaut.
Output
Générer des modèles de sortie, un modèle ou des arbres AST. Cette option est disponible uniquement pour les grammaires qui contiennent des analyseurs syntaxiques et un analyseur d'arbres. La valeur par défaut est de ne rien générer.
Backtrack
Lorsque sa valeur est True, cette option indique que ANTLR devrait revenir lorsque l'analyse statique de la grammaire LL (*) ne parvient pas à obtenir une décision déterministe. Cette option est habituellement utilisée en conjonction avec l'option memoize. La valeur par défaut est False.
Memoize
Enregistrer les résultats partiels d'analyse pour garantir que pour tout retour en arrière, l'analyseur n'analyse jamais la même entrée avec la même règle plus d'une fois. Ceci garantit une vitesse d'analyse linéaire au prix de la mémoire non linéaire. La valeur par défaut est False.
tokenVocab
Indiquez comment ANTLR devrait nommer l'ensemble de tokens prédéfinis ou générés. Cela sera nécessaire pour une grammaire qui veut utiliser les tokens d'une autre. Typiquement, une grammaire d'arbre utilisera les tokens de la grammaire de l'analyseur qui crée ses arbres. La valeur par défaut aucun.
rewrite
Lorsque la sortie de votre traducteur ressemble beaucoup à l'entrée, la solution la plus simple consiste à modifier le tampon d'entrée en place. Recréer toutes les entrées avec des actions juste pour modifier une petite partie est très fastidieux. Rewrite s'utilise conjointement avec l'option « output = Template ». Lorsque vous utilisez « rewrite = true », l'analyseur remplace également l'entrée à traiter par la règle avec le modèle. La valeur par défaut est faux.
SuperClass
Spécifie la superclasse de l'analyseur généré. Ce n'est pas une super grammaire ! Cette option affecte seulement la génération du code. La valeur par défaut est Lexer, Parser, ou TreeParser selon le type de grammaire.
Filter
À utiliser pour le LEXER uniquement. Toutes les règles du lexer sont essayées dans l'ordre indiqué, à la recherche d'une partie du flux d'entrée. Après la recherche de la règle convenable, la méthode nextToken () retourne le Token généré de cette règle. Si aucune règle ne correspond, le lexer consomme un seul caractère et continue à chercher la règle convenable. La valeur par défaut False.
K
Limite l'analyseur généré de cette grammaire à utiliser une profondeur maximale d'anticipation de la valeur de k. Ceci transforme l'analyse LL(*) classique en une analyse LL(k). La valeur par défaut est * pour une grammaire LL(*).
Voici quelques exemples d'options
K = 2; // Mettre la valeur d'anticipation à 2
tokenVocabulary = Calco; // Appeler le vocabulaire généré "Calco"
defaultErrorHandler = false; // Ne pas générer les erreurs du parser.3-6. Lever les ambigüités▲
Deux règles sont ambigües lorsqu'elles commencent par les mêmes caractères. Par exemple, il sera difficile pour l'analyseur de savoir laquelle des règles suivantes appliquer lorsqu'il rencontre le caractère ‘a' dans le flux d'entrée.
RULE1 : "ab" ;
RULE2 : "ac" ;Pour lever les ambigüités, deux techniques peuvent être utilisées : la valeur d'anticipation et le prédicat sémantique.
3-6-a. La valeur d'anticipation▲
Il s'agit du nombre de tokens que l'analyseur prendra en compte dans le flux d'entrée pour déterminer la règle à appliquer.
Par exemple, pour lever l'ambigüité entre les règles RULE1 et RULE2 ci-dessus, il suffit de définir dans les options la valeur d'anticipation à 2. De ce fait, l'analyseur ne se focalisera plus sur le premier caractère seulement, mais étudiera les deux premiers caractères pour trancher sur la règle à appliquer.
Par défaut la valeur d'anticipation est à 1. Vous pourrez l'augmenter pour lever des ambigüités. Pour modifier la valeur d'anticipation, il faut définir l'option
k = <valeur d'anticipation>
dans la partie Option qui suit la déclaration de l'analyseur.
3-6-b. Le prédicat sémantique▲
Très souvent, la valeur d'anticipation est impuissante pour lever des ambigüités sur des règles qui commencent toutes par les mêmes suites de caractères, surtout lorsque ces suites sont très longues. Dans ce cas, il faut regrouper ces règles en une seule règle à plusieurs alternatives (chaque règle étant une alternative) et utiliser le prédicat sémantique (=>).
Par exemple :
DOB
: ('0'..'9' '0'..'9' '/')=>
(('0'..'9')('0'..'9')'/')(('0'..'9')('0'..'9')'/')('0'..'9')('0'..'9')
| ('0'..'9')+
;Ici, l'analyseur étudiera d'abord l'expression ('0'..'9' '0'..'9' '/'). Si elle est reconnue dans le texte d'entrée, c'est la première alternative de la règle qui sera appliquée. Dans le cas contraire, c'est la dernière alternative.
3-7. Les actions ▲
Antlr permet d'ajouter aux règles des instructions écrites dans le langage cible. Ces instructions sont appelées actions.
Une action est définie entre accolades et peut être ajoutée :
- au début de la règle . Ainsi l'action sera exécutée lorsque l'analyseur rencontrera cette règle ;
- dans le corps de la règle : l'action sera exécutée pendant le traitement de la règle.
Exemple
ENTIER {System.out.println ("un entier est rencontré"); }// action au début
: (‘0'…'9')+ {System.out.println ("traitement de l'entier"); }
// action dans le corps
;Une action peut être constituée d'instructions simples ou d'une suite d'instructions plus ou moins complexes portant aussi bien sur des opérations mathématiques que sur des accès à des fichiers ou à une base de données. Cependant, pour la lisibilité et l'efficacité de la grammaire, il faut éviter d'ajouter des actions complexes ou trop longues. Il vaudrait mieux définir les traitements par des procédures dans un autre fichier ou paquetage et appeler ces procédures comme actions dans les règles.
4. Définition des analyseurs▲
Comme nous l'avons dit plus haut, il existe principalement trois types d'analyseurs : l'analyseur lexical, l'analyseur syntaxique et l'analyseur d'arbre. Chaque analyseur peut être défini dans un fichier grammatical isolé, de même que les trois peuvent être définis dans le même fichier. Les fichiers grammaticaux doivent avoir l'extension « .g ».
4-1. Définition de l'analyseur lexical (le lexer)▲
L'analyseur lexical définit les règles qui seront appliquées pour le regroupement des flux de caractères en flux de tokens. C'est une sous-classe de la classe Lexer. Par convention, le nom des règles doit être en majuscules.
La syntaxe de définition d'un analyseur lexical est la suivante :
Class nom_de_la_classe extends Lexer;
options{ // ici les options spécifiques au lexer }
tokens{
// Définir ici les tokens imaginaires ou littéraux
}
/*Définition des règles de l'analyseur*/
REGLE1: corps de la règle;
….
REGLE_N: corps de la règle;4-2. Définition de l'analyseur syntaxique (le parser)▲
L'analyseur syntaxique définit les règles de regroupement des tokens en constructions syntaxiquement correctes. C'est une sous-classe de Parser. Le nom des règles doit être de préférence en minuscules.
Class nom_de_la_classe extends Parser;
options{ // ici les options spécifiques au Parser}
tokens{
// Définir ici les tokens imaginaires ou littéraux
}
/*Définition des règles de la classe ici (voir paragraphe suivant pour la syntaxe)*/
regle1: corps de la règle;
….
regle n: corps de la règle;4-3. L'analyseur d'arbre (le TreeParser)▲
Lors de l'écriture des règles dans les analyseurs lexical et syntaxique, on peut demander la génération automatique d'un arbre syntaxique. Il suffit de définir l'option
Build AST =true;
dans la partie Options de l'analyseur syntaxique.
Cet arbre syntaxique constitue aussi un flux d'entrée dont les tokens sont les nœuds de l'arbre et les constructions syntaxiques sont les branches ou les sous-arbres. Pour analyser ce nouveau flux de nœuds, Antlr a prévu l'analyseur d'arbre.
L'analyseur d'arbre hérite de la classe TreeParser.
Class nom_de_la_classe extends TreeParser;
options{ // ici les options spécifiques au Parser}
tokens{
// Définir ici les tokens imaginaires ou littéraux
}
/*Définition des règles de la classe ici (voir paragraphe suivant pour la syntaxe)*/
regle1: corps de la règle;
….
regle n: corps de la règle;Nous reviendrons sur la construction et l'analyse de l'arbre syntaxique dans une prochaine édition.
5. Générer les analyseurs à partir de la grammaire▲
Une fois les analyseurs définis dans une grammaire et enregistrés dans un ou plusieurs fichiers d'extension « .g », Antlr peut générer des analyseurs correspondants dans l'un de ses langages cibles (Java par exemple). Pour cela, il faudra paramétrer un fichier « build.xml » qui contiendra les directives à suivre lors de la compilation. Les analyseurs ainsi générés pourront être intégrés dans le programme principal pour réaliser les opérations attendues.
5-1. Le fichier Build.xml▲
Le fichier Build.xml définit les tâches qui seront exécutées par Apache Ant pour générer les analyseurs à partir de la grammaire Antlr. Le paramétrage d'un fichier build.xml peut faire l'objet d'un tutoriel à lui seul. Cependant, le moins qu'on puisse retenir est qu'il est organisé en trois rubriques :
- dans la rubrique Properties définir les variables à utiliser dans les autres rubriques. Ces variables contiennent notamment les chemins des répertoires. Par exemple, les variables « grammar.dir » et « parser.projet » ci-dessous contiennent les chemins vers le fichier grammaire et vers le dossier qui stockera les analyseurs générés ;
- dans la rubrique Tasks, définir les tâches à exécuter par Ant. La tâche que nous définirons est « antlrTask » qui compilera la grammaire ;
- dans la rubrique Target, préciser les cibles à atteindre pour accomplir ces tâches. Dans notre exemple, trois cibles ont été précisées : la cible « antlrproject » pour la génération des analyseurs, la cible « deleteAntlrProject » pour supprimer les fichiers générés et la cible « regenAntlrProject » qui est la cible par défaut. Elle efface les anciens analyseurs générés puis en génère de nouveaux.
La ligne qui précède ces trois rubriques précise le nom du projet (calculatriceANTLR), la cible par défaut à atteindre (regenAntlrProject) et le répertoire racine (« . » , c'est-à-dire le répertoire courant, celui qui contient le fichier Build.xml).
À titre d'illustration, voici le fichier Build.xml que nous utiliserons dans le cas pratique de la section suivante.
<?xml version="1.0" encoding="UTF-8"?>
<project name="calculatriceANTLR" default="regenAntlrProject" basedir=".">
<!-- ######### PROPERTY ##############-->
<!-- set global properties for this build -->
<property name="src.dir" value="src" />
<property name="grammar.dir" value="${src.dir}/main/ant" />
<property name="lib.dir" value="lib" />
<property name="parser.project" value="${src.dir}/main/java/analyseur" />
<!-- ############### TASKS ##################-->
<taskdef name="antlrtask"
classname="org.apache.tools.ant.taskdefs.optional.ANTLR">
<classpath>
<pathelement path="${compile_classpath}"/>
</classpath>
</taskdef>
<!-- ########### TARGETS ####################-->
<target name="antlrProject">
<!-- Calculator grammar /-->
<antlrtask target="${grammar.dir}/grammar.g"
outputdirectory="${parser.project}" />
</target>
<target name="regenAntlrProject" depends="deleteAntlrProject, antlrProject" />
<target name="deleteAntlrProject">
<delete>
<fileset dir="${parser.project}" />
</delete>
</target>
</project>5-2. La compilation▲
5-2-a. Installation du compilateur Ant▲
Pour compiler les grammaires Antlr et générer les analyseurs, on peut utiliser le compilateur de Apache Ant. En effet, Ant comprend une bibliothèque (ant-antlr) qui sera utilisée pour la génération des analyseurs à partir de la grammaire Antlr. Pour installer Ant sous Windows :
- Télécharger la dernière version de Ant en suivant le lien http://ant.apache.org ;
- Décompresser le fichier téléchargé dans un répertoire ;
- Définir une variable d'environnement ANT_HOME avec comme valeur le chemin du répertoire dans lequel vous avez décompressé Ant ;
- Définir ou modifier la variable d'environnement PATH en y ajoutant le chemin %ANT_HOME%/bin ;
Pour vérifier que l'installation s'est bien passée, en ligne de commande, exécuter la commande ant -version .
5-2-b. Compiler le build.xml▲
Sous Windows, aller en ligne de commande, se placer dans le répertoire qui contient le fichier build.xml et exécuter la commande ant .
Les directives définies dans le build.xml seront suivies et les analyseurs seront générés dans le répertoire spécifié.
5-3. Fichiers générés▲
Une fois la compilation réussie, Ant génère un ensemble de fichiers. Il s'agit notamment :
- d'une classe pour le parser ;
- d'une classe pour le lexer ;
- d'une ou plusieurs classes pour les tokens générés XXXTokensType.java.
5-4. Exploitation des analyseurs générés▲
Le lexer et le parser générés doivent être maintenant exploités dans le programme principal pour effectuer le travail d'analyse attendu. En Java, l'exploitation des analyseurs générés se fait en trois étapes :
- Créer un objet de la classe de l'analyseur lexical à partir d'un flux d'entrée ;
- Créer un objet de la classe de l'analyseur syntaxique à partir de l'objet analyseur lexical ;
- Appeler la première méthode de l'analyseur syntaxique générée pour lancer l'analyse. Cette méthode correspond en fait à sa première règle dans la grammaire. Comme cet appel peut générer des erreurs, il est commode de le faire dans un bloc « try...catch » comme suit :
public static void main (String [] args) {
String expression
/*1- création de l'analyseur lexical à partir du flux d'entrée*/
XXXLexer lexer = new XXXLexer(new StringReader(expression));
/* 2- Création d'un analyseur syntaxique à partir de l'analyseur lexical */
CalculatriceParser parser = new CalculatriceParser(lexer);
try {
/ * 3- Appel de la première règle de l'analyseur syntaxique */
parser.regle1();
} catch(Exception e)
{
System.out.println("Erreur de saisie");
}
//………. suite du programme principal6. Cas pratique▲
Pour un débutant, la meilleure façon d'appréhender l'outil ANTLR est de partir d'un exemple pour bâtir ses propres analyseurs.
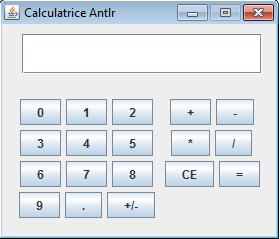
Afin d'illustrer les notions ci-dessus exposées, nous allons concevoir en Java, une calculatrice qui effectue les opérations arithmétiques de base : addition, multiplication, soustraction et division des entiers. L'utilisateur saisira l'expression à calculer et le programme lui affichera le résultat. L'interface graphique de notre calculatrice ressemblera à quelque chose du genre
Vous vous demandez sans doute quel intérêt il y a à définir des analyseurs pour réaliser un aussi petit projet qui peut être efficacement fait juste par une manipulation des primitives sur les chaînes de caractères. Vous avez sans doute raison. Cependant, si l'expression à calculer contient plusieurs opérateurs et des parenthèses, et s'il faut tenir compte de la priorité des opérateurs, vous convenez avec nous que l'utilisation des primitives de manipulation des chaînes de caractères deviendra fastidieuse. De plus, avec ces dernières, vous n'avez aucun moyen de vérifier que l'expression saisie par l'utilisateur est bien une expression arithmétique syntaxiquement correcte. C'est là que s'exprime toute la puissance des analyseurs.
Grâce aux analyseurs qui seront générés de notre grammaire par Antlr, notre programme sera capable :
- de reconnaître les termes de l'expression arithmétique à calculer ;
- de l'analyser pour savoir si elle est correctement écrite ;
-
d'effectuer les opérations souhaitées et d'afficher le résultat.
Pour y parvenir, nous devons d'abord préparer notre environnement de travail.
6-1. Configurations de base▲
Tout d'abord, vous devez vous assurer que le compilateur du langage cible (ici le JDK) est bien installé, ainsi que l'EDI (Eclipse).
Nous voulons créer un projet Maven sous Eclipse, mais vous pouvez aussi vous contenter d'un projet Java simple. Nous choisissons un projet Maven pour la simple raison que le plugin Apache Maven facilite l'organisation et l'assemblage d'un projet en gérant les dépendances entre les différents modules.
Au cas où vous souhaitez aussi vous en servir, vous procéderez à l'installation de Maven en suivant la procédure suivante :
- Télécharger Maven dans le site http://maven.apache.org/ ;
- Décompresser le fichier téléchargé dans un répertoire de votre ordinateur ;
- Définir une variable d'environnement M2_HOMEavec pour valeur le chemin du répertoire dans lequel vous avez installé Maven ;
- Définir une variable d'environnement utilisateur M2avec pour valeur%M2_HOME%\bin;
- Créer ou mettre à jour la variable d'environnement PATH avec pour valeur %M2%;
- En ligne de commande, exécuter mvn versionpour vérifier que l'installation s'est passée correctement.
6-2. Notre démarche▲
En suivant les recommandations du paragraphe 1.6, nous allons procéder en cinq étapes :
- Création un projet sous Eclipse ;
- Création des packages. Dans un package (Application) de notre projet nous définirons deux classes : une classe Tools contenant les fonctions arithmétiques (addition, multiplication, division et soustraction) et une classe principale (Frame) implémentera l'interface graphique. Un autre package (Parser), accueillera les classes générées par Antlr ;
- Écriture de la grammaire dans un fichier .g ;
- Paramétrage du fichier build.xml ;
- Génération et exploitation des analyseurs.
6-3. Réalisation du projet▲
6-3-a. Création d'un nouveau projet sous Eclipse▲
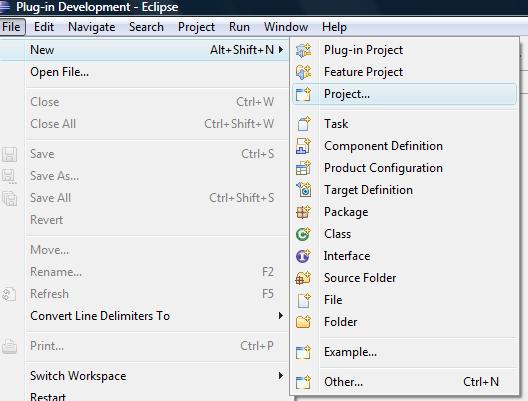
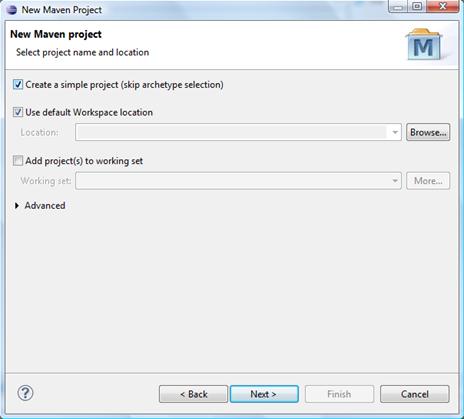
Pour créer un nouveau projet avec Maven sous Eclipse :
- dans le menu Fichier, pointer sur Nouveau et cliquer sur Projet ;
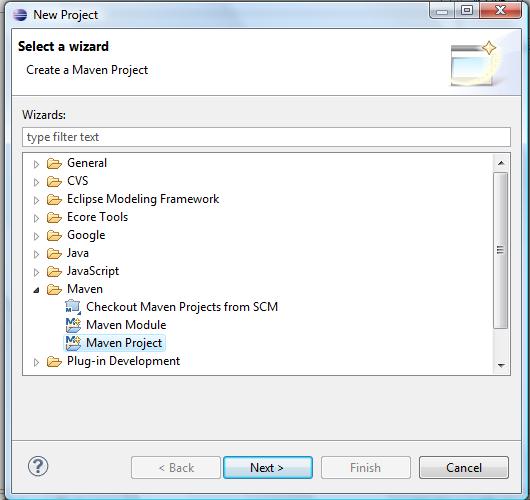
- parmi les types de projets, choisir Maven Project et cliquer sur Suivant ;
- choisir créer un simple projet Maven ;
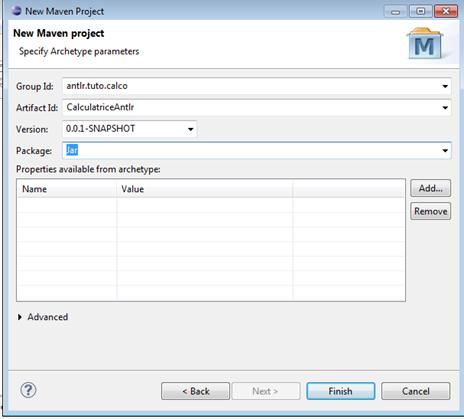
- donner un nom au projet ( CalculatriceAntlr ) ;
- cliquer sur Terminer .
6-3-b. Création des packages▲
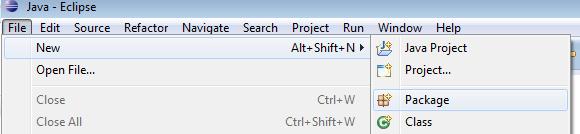
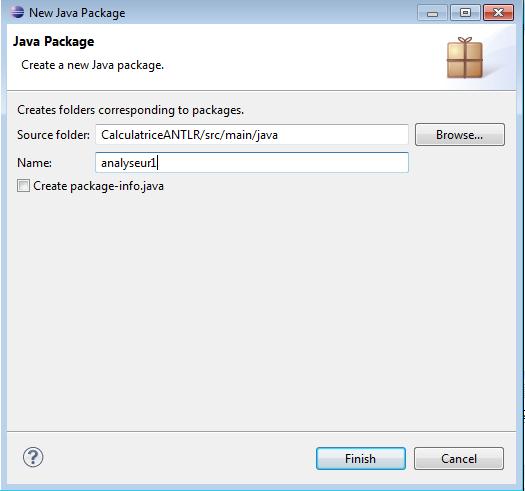
Cliquons sur le répertoire src/main/java de notre projet et créons deux packages nommés « Application » et « Analyseur ».
- Dans le menu Fichier, pointer sur Nouveau et cliquer sur Package.
- Saisir le nom du package et cliquer sur Terminer .
6-3-c. Écriture de la grammaire▲
- L'analyseur lexical
Pour ce qui est de notre projet de calculatrice, il faut d'abord recenser les lexèmes à reconnaître dans une expression à calculer. En effet, l'utilisateur de la calculatrice aura à saisir des nombres entiers et des opérateurs, avec éventuellement des espaces. Notre analyseur lexical devra donc définir des règles pour la reconnaissance de ces lexèmes. Sa structure est la suivante :
class CalculatriceLexer extends Lexer
Options {
K=1 ;
filter = true ;
}
INT
: (‘0'..'9')+ // un entier est constitué d'un ou plusieurs chiffres décimaux
;
PLUS : ‘+' ;
MINUS : ‘-‘ ;
PRODUCT : ‘x' ;
DIV : ‘/' ;
WS // cette règle permet de reconnaître les espacements
:
( ' '
| '\t'
| '\r' '\n' { newline(); }
| '\n' { newline(); }
)
{ $setType(Token.SKIP); } // ne pas considérer ces espacements comme tokens
;- L'analyseur syntaxique
Le parser de notre projet devra être en mesure de reconnaître des expressions qui traduisent une addition, une soustraction, une multiplication ou une division.
class CalculatriceParser extends Parser;
options
{
exportVocab=CALCO;
buildAST=false;
k=2;
}
{
public int resultat; // cette variable stockera le résultat de l'opération
}
expr
: addExpr|subExpr|multExpr|divExpr // l'expression à analyser sera soit une
// addition, une soustraction, une multiplication ou une division
;
addExpr
{int n,m;}
: (a:INT PLUS b:INT)
{ n=Integer.parseInt(a.getText()); // transformation de la chaine de caractères en entier
m=Integer.parseInt(b.getText());
resultat=sum(n,m);
}
;
subExpr
{int n,m;}
: (a:INT MINUS b:INT)
{ n=Integer.parseInt(a.getText());
m=Integer.parseInt(b.getText());
resultat=substract(n,m);
}
;
multExpr
{int n,m;}
: (a:INT PRODUCT b:INT)
{ n=Integer.parseInt(a.getText());
m=Integer.parseInt(b.getText());
resultat=multiply(n,m);
}
;
divExpr
{int n,m;}
: (a:INT DIVIDE b:INT)
{ n=Integer.parseInt(a.getText());
m=Integer.parseInt(b.getText());
resultat=divide(n,m);
}
;Les fonctions add(), substract(), multiply() et divide() sont implémentées dans la classe Tools du paquetage Application. On aurait bien pu se contenter d'effectuer ces opérations directement dans la grammaire. Mais souvenez-vous que l'objectif est de ne pas surcharger les règles de la grammaire par des actions aux longues instructions.
Nous enregistrerons notre grammaire sous le nom grammar.g dans le répertoire « src/Ant » de notre projet Eclipse. La grammaire complète se trouve dans le code complet de l'application que vous téléchargerez.
6-3-d. Paramétrage du Build.xml ▲
<?xml version="1.0" encoding="UTF-8"?>
<project name="calculatriceANTLR" default="regenAntlrProject" basedir=".">
<!-- ############################# VARIABLES ##############################-->
<!-- set global properties for this build -->
<property name="src.dir" value="src" />
<property name="grammar.dir" value="${src.dir}/main/ant" />
<property name="lib.dir" value="lib" />
<property name="parser.project" value="${src.dir}/main/java/analyseur" />
<!-- ############################# TASKS ##############################-->
<taskdef name="antlrtask"
classname="org.apache.tools.ant.taskdefs.optional.ANTLR">
<classpath>
<pathelement path="${compile_classpath}"/>
</classpath>
</taskdef>
<!-- ############################ TARGETS #############################-->
<target name="antlrProject">
<!-- Calculator grammar /-->
<antlrtask target="${grammar.dir}/grammar.g"
outputdirectory="${parser.project}" />
</target>
<target name="regenAntlrProject" depends="deleteAntlrProject, antlrProject" />
<target name="deleteAntlrProject">
<delete>
<fileset dir="${parser.project}" />
</delete>
</target>
</project>6-3-e. La génération▲
Vous pouvez générer les analyseurs à partir de la grammaire en utilisant le compilateur Ant ou Maven.
- Avec le compilateur Ant
En ligne de commande, se placer dans le répertoire qui contient le fichier build.xml et exécuter la commande ant .
- Avec Maven
En ligne de commande, se placer dans le répertoire qui contient le projet et exécuter la commande mvn clean package .
Une fois la compilation réussie, vous pouvez observer les analyseurs générés en ouvrant le package « Analyseurs » du projet. Vous pourrez alors observer :
- une classe pour le parser : CalculatriceParser.java ;
- une classe pour le lexer : CalculatriceLexer.java ;
- une classe pour les tokens générés : CalculatriceLexerTokensType.java ;
- d'autres fichiers (.txt, .smap) nécessaires à l'analyse.
6-3-f. Exécution du projet▲
Le lexer et le parser générés doivent être maintenant exploités dans la classe principale pour effectuer le travail attendu (opérations arithmétiques). Pour notre exemple, c'est la classe principale Frame qui s'en chargera. En faisant abstraction du code graphique, voici la méthode qui fera appel aux analyseurs une fois l'expression saisie et que l'utilisateur aura cliqué sur le bouton « = ». Le code complet de notre calculatrice Antlr peut être téléchargé en cliquant sur le lien ci-dessous situé à l'entête.
 Sélectionnez
Sélectionnezint compute(String expression){
int result =0;
CalculatriceLexer lexer = new CalculatriceLexer(new StringReader(expression));
CalculatriceParser parser = new CalculatriceParser(lexer);
try {
parser.expr();
result = parser.resultat;
} catch(Exception e)
{
System.out.println("Erreur de saisie");
}
return result;7. Conclusion▲
À l'aide de ce tutoriel, vous avez appris à générer un analyseur lexical et un analyseur syntaxique avec l'outil Antlr et à l'utiliser dans une application Java. Pour appliquer les notions exposées, nous avons défini une grammaire pour générer un analyseur lexical et un analyseur syntaxique que nous avons utilisés pour implémenter une application de calculatrice simple.
Cependant, notre calculatrice n'est pas en mesure d'effectuer les opérations comportant des parenthèses ou plusieurs opérateurs (2*5+10/3) et de tenir compte des priorités entre opérateurs. Pour rendre cela possible, nous utiliserons une des grandes forces de Antlr, la possibilité de construire un arbre syntaxique et de définir un analyseur d'arbres. Ces aspects feront l'objet du prochain article.
8. Liens▲
http://javadude.com/articles/antlrtut/ .
http://antlreclipse.sourceforge.net/ .
http://supportweb.cs.bham.ac.uk/documentation/tutorials/docsystem/build/tutorials/antlr/antlr.html .
9. Articles▲
- Karl Stroetmann, Antlr | Another Tutorial, Octobre 17, 2005
http://wwwlehre.dhbw-stuttgart.de/~stroetma/Skripten/antlr.pdf.
- Terence Parr, The Definitive ANTLR Reference, mai 2007.
- Tobias GUTZMANN, Getting Started with ANTLR, October 2010
http://www.st.cs.uni-saarland.de/edu/sopra/2010/ANTLRtutorial.pdf.
- Ashley J.S Mills, Support de cours sur Antlr, The University Of Birmingham, 2005
http://supportweb.cs.bham.ac.uk/documentation/tutorials/docsystem/build/tutorials/antlr/antlr.html .
10. Remerciements▲
Nous remercions du fond du cœur toutes les personnes qui, par leurs lectures et leurs remarques nous ont permis d'améliorer ce tutoriel, aussi bien du point de vue technique qu'orthographique. Nous pensons particulièrement à :
- Mickaël BARON ;
- Claude LELOUP ;
- Raymond (ram-0000).
- Yann Caron